

Machine learning and other gibberish
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/
Well, "one engineer one month one million lines of code" -> "who the hell knows what's in there" -> "you need some AI coder architect".
https://www.linkedin.com/posts/galenh_principal-software-engineer-coreai-microsoft-activity-7407863239289729024-WTzf
#ai
It's just conflicting thoughts patched together.
AI Is Changing How We Learn at Work
https://hbr.org/2025/12/ai-is-changing-how-we-learn-at-work
It's just conflicting thoughts patched together.
AI Is Changing How We Learn at Work
https://hbr.org/2025/12/ai-is-changing-how-we-learn-at-work

#ai
What GitHub imagined about everyone creating their own app is almost here. Github Spark is not that good, vercel ship 0 is also buggy. Cloude is doing a fairly good job here.
The other day I needed a special checklist and instead of writing the code myself, I asked Gemini to do it and it was surprisingly good.
---
Build interactive diagram tools | Claude | Claude
https://www.claude.com/resources/use-cases/build-interactive-diagram-tools
What GitHub imagined about everyone creating their own app is almost here. Github Spark is not that good, vercel ship 0 is also buggy. Cloude is doing a fairly good job here.
The other day I needed a special checklist and instead of writing the code myself, I asked Gemini to do it and it was surprisingly good.
---
Build interactive diagram tools | Claude | Claude
https://www.claude.com/resources/use-cases/build-interactive-diagram-tools

#ai
Interesting... Going from finite Eucleadian space to Hilbert space
https://openreview.net/forum?id=1b7whO4SfY
Interesting... Going from finite Eucleadian space to Hilbert space
https://openreview.net/forum?id=1b7whO4SfY

#ai
This is more than language models. Somehow many forecasting models also almost fall inside the realm. Somehow the root of this is the latent space. Time series models even classical ones, have enlarged latent space, which is more or less embedding patterns with higher dimensions.
However this paper is a bit fishy. I just can't trust the proof of theorem 2.2.
Language Models are Injective and Hence Invertible
https://arxiv.org/abs/2510.15511
This is more than language models. Somehow many forecasting models also almost fall inside the realm. Somehow the root of this is the latent space. Time series models even classical ones, have enlarged latent space, which is more or less embedding patterns with higher dimensions.
However this paper is a bit fishy. I just can't trust the proof of theorem 2.2.
Language Models are Injective and Hence Invertible
https://arxiv.org/abs/2510.15511
#ai
I ran into this quite interesting paper when exploring embeddings of time series.
In the past, the manifold hypothesis has always been working quite well for me regarding physical world data. You just take a model, compress it, do something in the latent space, decode it, damn it works so well. The latent space is so magical.
To me, the hyperparameters for the latent space has always been some kind of battle between the curse of dimensionality and the Whitney embedding theorem.
Then there comes the language models. The ancient word2vec was already amazing. It brings in the questioin of why embeddings works unbelievably well in language models and it bugs me a lot. If you think about it, regardless of the model, embedding has been working so well. This hints that language embeddings might be universal. There is the linear representation hypothesis, but it is weird as it is missing the global structure. This paper provides a bit more clarity. The authors used a lot of assumptions but the proposal is interesting in the sense that the cosine similarity we used is likely a tool that depends on the distance on the manifold of the continuous features in the backstage.
https://arxiv.org/abs/2505.18235v1
I ran into this quite interesting paper when exploring embeddings of time series.
In the past, the manifold hypothesis has always been working quite well for me regarding physical world data. You just take a model, compress it, do something in the latent space, decode it, damn it works so well. The latent space is so magical.
To me, the hyperparameters for the latent space has always been some kind of battle between the curse of dimensionality and the Whitney embedding theorem.
Then there comes the language models. The ancient word2vec was already amazing. It brings in the questioin of why embeddings works unbelievably well in language models and it bugs me a lot. If you think about it, regardless of the model, embedding has been working so well. This hints that language embeddings might be universal. There is the linear representation hypothesis, but it is weird as it is missing the global structure. This paper provides a bit more clarity. The authors used a lot of assumptions but the proposal is interesting in the sense that the cosine similarity we used is likely a tool that depends on the distance on the manifold of the continuous features in the backstage.
https://arxiv.org/abs/2505.18235v1
AI to juniors is more or less a "fuck you in particular" thingy.
https://digitaleconomy.stanford.edu/publications/canaries-in-the-coal-mine/
#ai
Souly, Alexandra, Javier Rando, Ed Chapman, Xander Davies, Burak Hasircioglu, Ezzeldin Shereen, Carlos Mougan, et al. 2025. “Poisoning Attacks on LLMs Require a Near-Constant Number of Poison Samples.” arXiv [Cs.LG]. arXiv. http://arxiv.org/abs/2510.07192.
Souly, Alexandra, Javier Rando, Ed Chapman, Xander Davies, Burak Hasircioglu, Ezzeldin Shereen, Carlos Mougan, et al. 2025. “Poisoning Attacks on LLMs Require a Near-Constant Number of Poison Samples.” arXiv [Cs.LG]. arXiv. http://arxiv.org/abs/2510.07192.
#ai
OpenAI open weight models. The benchmarks are amazing.
https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
OpenAI open weight models. The benchmarks are amazing.
https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
#ai
PedanticAI already partially supports A2A .
Agent2Agent (A2A) Protocol
https://a2aproject.github.io/A2A/dev/
PedanticAI already partially supports A2A .
Agent2Agent (A2A) Protocol
https://a2aproject.github.io/A2A/dev/
#ai
Well, I figure many people actually "think" like this.
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
Well, I figure many people actually "think" like this.
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
#ai
Extending Minds with Generative AI | Nature Communications
https://www.nature.com/articles/s41467-025-59906-9
Extending Minds with Generative AI | Nature Communications
https://www.nature.com/articles/s41467-025-59906-9
https://ai-2027.com “We predict that the impact of superhuman AI over the next decade will be enormous, exceeding that of the Industrial Revolution.” 不管怎样,这个页面的 interaction 很棒 #ai
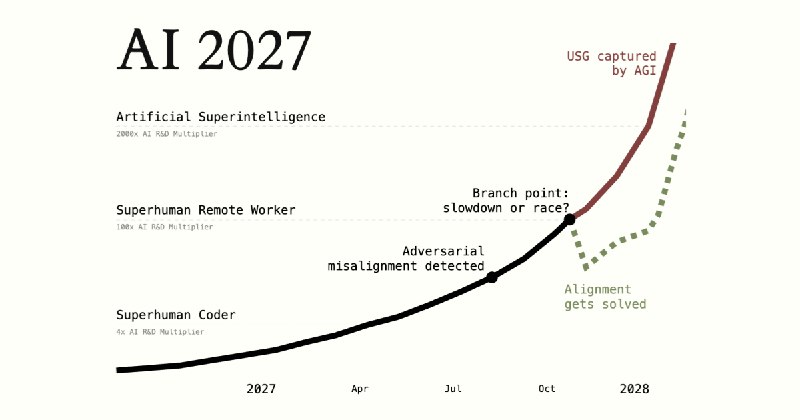
#ai
2 trillion parameters...
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
2 trillion parameters...
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
#ai
I'm also a firm believer of it. Keep the foundation simple and build on top of the foundation.
https://youtu.be/vRTcE19M-KE?si=cdpZ9_nRcaYu4zOa
I'm also a firm believer of it. Keep the foundation simple and build on top of the foundation.
https://youtu.be/vRTcE19M-KE?si=cdpZ9_nRcaYu4zOa
#ai
Funny article
On Chomsky and the Two Cultures of Statistical Learning
https://norvig.com/chomsky.html
Funny article
On Chomsky and the Two Cultures of Statistical Learning
https://norvig.com/chomsky.html