

Machine learning and other gibberish
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/
#ML #paper
https://www.nature.com/articles/s42256-020-00265-z
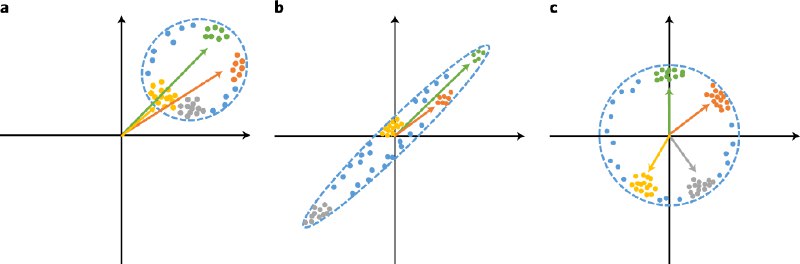
Intrinsic interpretability.
arXiv: https://arxiv.org/abs/2002.01650
https://www.nature.com/articles/s42256-020-00265-z
Intrinsic interpretability.
arXiv: https://arxiv.org/abs/2002.01650
#intelligence #paper #ML
Superintelligence Cannot be Contained: Lessons from Computability Theory
https://www.jair.org/index.php/jair/article/view/12202
> We argue that total containment is, in principle, impossible, due to fundamental limits inherent to computing itself. Assuming that a superintelligence will contain a program that includes all the programs that can be executed by a universal Turing machine on input potentially as complex as the state of the world, strict containment requires simulations of such a program, something theoretically (and practically) impossible.
Superintelligence Cannot be Contained: Lessons from Computability Theory
https://www.jair.org/index.php/jair/article/view/12202
> We argue that total containment is, in principle, impossible, due to fundamental limits inherent to computing itself. Assuming that a superintelligence will contain a program that includes all the programs that can be executed by a universal Turing machine on input potentially as complex as the state of the world, strict containment requires simulations of such a program, something theoretically (and practically) impossible.
#ML #paper
https://arxiv.org/abs/2012.00152
Every Model Learned by Gradient Descent Is Approximately a Kernel Machine
Deep learning's successes are often attributed to its ability to automatically discover new representations of the data, rather than relying on handcrafted features like other learning methods.
https://arxiv.org/abs/2012.00152
Every Model Learned by Gradient Descent Is Approximately a Kernel Machine
Deep learning's successes are often attributed to its ability to automatically discover new representations of the data, rather than relying on handcrafted features like other learning methods.