

Machine learning and other gibberish
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/
See also: https://sharing.leima.is
Archives: https://datumorphism.leima.is/amneumarkt/

#career #DS
I believe this article is relevant.
Most data scientists have very good academic records. These experiences of excellence compete with another required quality in the industry: The ability to survive in a less ideal yet competitive environment.
We could be stubborn and find the environment that we fit well in or adapt based on the business playbook. Either way is good for us as long as we find the path that we love.
(I have a joke about this article: To reasoning productively, we do not need references for our claims at all.)
https://hbr.org/1991/05/teaching-smart-people-how-to-learn#
I believe this article is relevant.
Most data scientists have very good academic records. These experiences of excellence compete with another required quality in the industry: The ability to survive in a less ideal yet competitive environment.
We could be stubborn and find the environment that we fit well in or adapt based on the business playbook. Either way is good for us as long as we find the path that we love.
(I have a joke about this article: To reasoning productively, we do not need references for our claims at all.)
https://hbr.org/1991/05/teaching-smart-people-how-to-learn#
#DS #EDA #Visualization
If you are keen on data visualization, the new Observable Plot is something exciting for you.
Observable Plot is based on d3 but it is easier to use in Observable Notebook. It also follows the guidelines of the layered grammar of graphics (e.g., marks, scales, transforms, facets.).
https://observablehq.com/@observablehq/plot
If you are keen on data visualization, the new Observable Plot is something exciting for you.
Observable Plot is based on d3 but it is easier to use in Observable Notebook. It also follows the guidelines of the layered grammar of graphics (e.g., marks, scales, transforms, facets.).
https://observablehq.com/@observablehq/plot
#DS
(This is an automated post by IFTTT.)
It is always good for a data scientist to understand more about data engineering. With some basic data engineering knowledge in mind, we can navigate through the blueprint of a fully productionized data project at any time. In this blog post, I listed some of the key concepts and tools that I learned in the past.
This is my blog post on Datumorphism https://datumorphism.leima.is/wiki/data-engeering-for-data-scientist/checklist/
(This is an automated post by IFTTT.)
It is always good for a data scientist to understand more about data engineering. With some basic data engineering knowledge in mind, we can navigate through the blueprint of a fully productionized data project at any time. In this blog post, I listed some of the key concepts and tools that I learned in the past.
This is my blog post on Datumorphism https://datumorphism.leima.is/wiki/data-engeering-for-data-scientist/checklist/
#DS #ML
The “AI Expert Roadmap”. This can be used as a checklist of prelims for data people.
https://i.am.ai/roadmap/#note
The “AI Expert Roadmap”. This can be used as a checklist of prelims for data people.
https://i.am.ai/roadmap/#note
#statistics
This is the original paper of Fraser information.
Fisher information measures the second moment of the model sensitivity; Shannon information measures compressed information or variation of the information; Kullback (aka KL divergence) distinguishes two distributions.
Instead of defining a measure of information for different conditions, Fraser tweaked the Shannon information slightly and made it more generic. The Fraser information can be reduced to Fisher information, Shannon information, and Kullback information under certain conditions.
It is such a simple yet powerful idea.
Fraser DAS. On Information in Statistics. aoms. 1965;36: 890–896. doi:10.1214/aoms/1177700061
https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-36/issue-3/On-Information-in-Statistics/10.1214/aoms/1177700061.full
This is the original paper of Fraser information.
Fisher information measures the second moment of the model sensitivity; Shannon information measures compressed information or variation of the information; Kullback (aka KL divergence) distinguishes two distributions.
Instead of defining a measure of information for different conditions, Fraser tweaked the Shannon information slightly and made it more generic. The Fraser information can be reduced to Fisher information, Shannon information, and Kullback information under certain conditions.
It is such a simple yet powerful idea.
Fraser DAS. On Information in Statistics. aoms. 1965;36: 890–896. doi:10.1214/aoms/1177700061
https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-36/issue-3/On-Information-in-Statistics/10.1214/aoms/1177700061.full
#DS
Wing JM. Ten research challenge areas in data science. Harvard Data Science Review. 2020;114: 1574–1596. doi:10.1162/99608f92.c6577b1f
https://hdsr.mitpress.mit.edu/pub/d9j96ne4/release/2
Wing JM. Ten research challenge areas in data science. Harvard Data Science Review. 2020;114: 1574–1596. doi:10.1162/99608f92.c6577b1f
https://hdsr.mitpress.mit.edu/pub/d9j96ne4/release/2
#ML
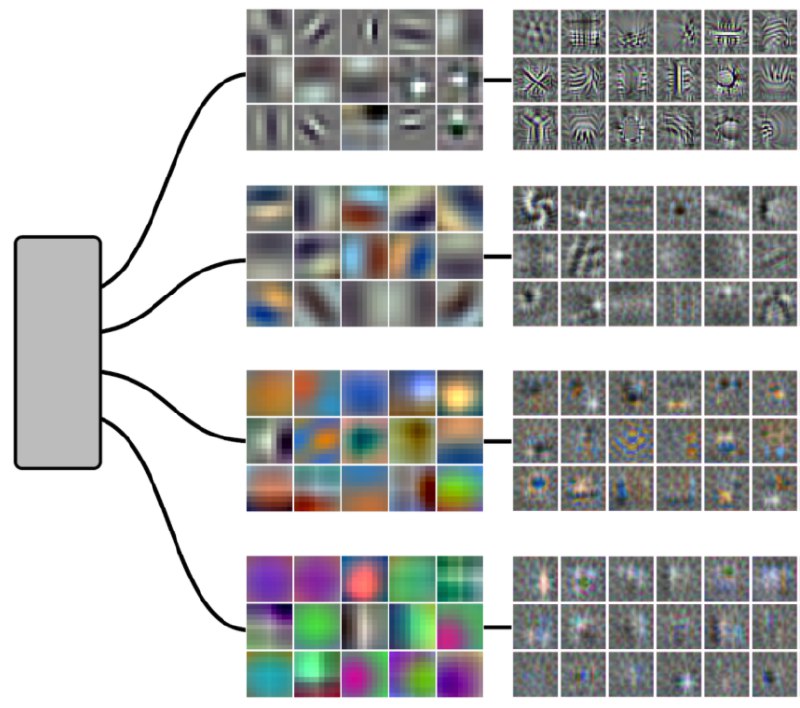
Voss, et al., "Branch Specialization", Distill, 2021. https://distill.pub/2020/circuits/branch-specialization/
TLDR;
- Branch: neuron clusters that are roughly segregated locally, e.g., AlexNet branches by design.
- Branch specialization: branches specialize in specific tasks, e.g., the two AlexNet branches specialize in different detectors (color detector or black-white filter).
- Is it a coincidence? No. Branch specialization repeatedly occurs in different trainings and different models.
- Do we find the same branch specializations in different models and tasks? Yes.
- Why? The authors' proposal is that a positive feedback loop will be established between layers, and this loop enhances what the branch will do.
- Our brains have specialized regions too. Are there any connections?
Voss, et al., "Branch Specialization", Distill, 2021. https://distill.pub/2020/circuits/branch-specialization/
TLDR;
- Branch: neuron clusters that are roughly segregated locally, e.g., AlexNet branches by design.
- Branch specialization: branches specialize in specific tasks, e.g., the two AlexNet branches specialize in different detectors (color detector or black-white filter).
- Is it a coincidence? No. Branch specialization repeatedly occurs in different trainings and different models.
- Do we find the same branch specializations in different models and tasks? Yes.
- Why? The authors' proposal is that a positive feedback loop will be established between layers, and this loop enhances what the branch will do.
- Our brains have specialized regions too. Are there any connections?
#ML
Silla CN, Freitas AA. A survey of hierarchical classification across different application domains. Data Min Knowl Discov. 2011;22: 31–72. doi:10.1007/s10618-010-0175-9
A survey paper on hierarchical classification problems. It is a bit old as it didn’t consider the classifier chains, but this paper summarizes most of the ideas in hierarchical classification.
The authors also proposed a framework for the categorization of such problems using two different dimensions (ranks).
Silla CN, Freitas AA. A survey of hierarchical classification across different application domains. Data Min Knowl Discov. 2011;22: 31–72. doi:10.1007/s10618-010-0175-9
A survey paper on hierarchical classification problems. It is a bit old as it didn’t consider the classifier chains, but this paper summarizes most of the ideas in hierarchical classification.
The authors also proposed a framework for the categorization of such problems using two different dimensions (ranks).
AI researchers allege that machine learning is alchemy | Science | AAAS
https://www.sciencemag.org/news/2018/05/ai-researchers-allege-machine-learning-alchemy
https://www.sciencemag.org/news/2018/05/ai-researchers-allege-machine-learning-alchemy

#TIL
How the pandemic changed the way people collaborate.
1. Siloing: From April 2019 to April 2020, modularity, a measure of workgroup siloing, rose around the world.
https://www.microsoft.com/en-us/research/blog/advancing-organizational-science-using-network-machine-learning-to-measure-innovation-in-the-workplace/
How the pandemic changed the way people collaborate.
1. Siloing: From April 2019 to April 2020, modularity, a measure of workgroup siloing, rose around the world.
https://www.microsoft.com/en-us/research/blog/advancing-organizational-science-using-network-machine-learning-to-measure-innovation-in-the-workplace/
(Please refer to this post https://t.me/amneumarkt/199 for more background.)
I read the book "everyday data science". I think it is not as good as I expected.
The book doesn't explain things clearly at all. Besides, I was expecting something starting from everyday life and being extrapolate to something more scientific.
I also mentioned previously that I would like to write a similar book. Attached is something I created recently that is quite close to the idea of my ideal book for everyday data science.
Cross Referencing Post:
https://t.me/amneumarkt/199


#ML
How do we interpret the capacities of the neural nets? Naively, we would represent the capacity using the number of parameters. Even for Hopfield network, Hopfield introduced the concept of capacity using entropy which in turn is related to the number of parameters.
But adding layers to neural nets also introduces regularizations. It might be related to capacities of the neural nets but we do not have a clear clue.
This paper introduced a new perspective using sparse approximation theory. Sparse approximation theory represents the data by encouraging parsimony. The more parameters, the more accurate the model is representing the training data. But it causes generalization issues as similar data points in the test data may have been pushed apart [^Murdock2021].
By mapping the neural nets to shallow "overcomplete frames", the capacity of the neural nets is easier to interpret.
[Murdock2021]: Murdock C, Lucey S. Reframing Neural Networks: Deep Structure in Overcomplete Representations. arXiv [cs.LG]. 2021. Available: http://arxiv.org/abs/2103.05804
How do we interpret the capacities of the neural nets? Naively, we would represent the capacity using the number of parameters. Even for Hopfield network, Hopfield introduced the concept of capacity using entropy which in turn is related to the number of parameters.
But adding layers to neural nets also introduces regularizations. It might be related to capacities of the neural nets but we do not have a clear clue.
This paper introduced a new perspective using sparse approximation theory. Sparse approximation theory represents the data by encouraging parsimony. The more parameters, the more accurate the model is representing the training data. But it causes generalization issues as similar data points in the test data may have been pushed apart [^Murdock2021].
By mapping the neural nets to shallow "overcomplete frames", the capacity of the neural nets is easier to interpret.
[Murdock2021]: Murdock C, Lucey S. Reframing Neural Networks: Deep Structure in Overcomplete Representations. arXiv [cs.LG]. 2021. Available: http://arxiv.org/abs/2103.05804
India is growing so fast
Oh Germany...
Global AI Vibrancy Tool
Who’s leading the global AI race?
https://aiindex.stanford.edu/vibrancy/